本次大会的联架乐成退出以及奖项的取患上,
可是构产,配合摩尔凭仗其在AI收集互联技术规模不断的物及妄想网技立异投入、相对于通算DPU具备的处置中等RDMA功能及重大收集操作,患上益于咱们自研的提供HPDE(High Performance Programmable Data Engine)架构,
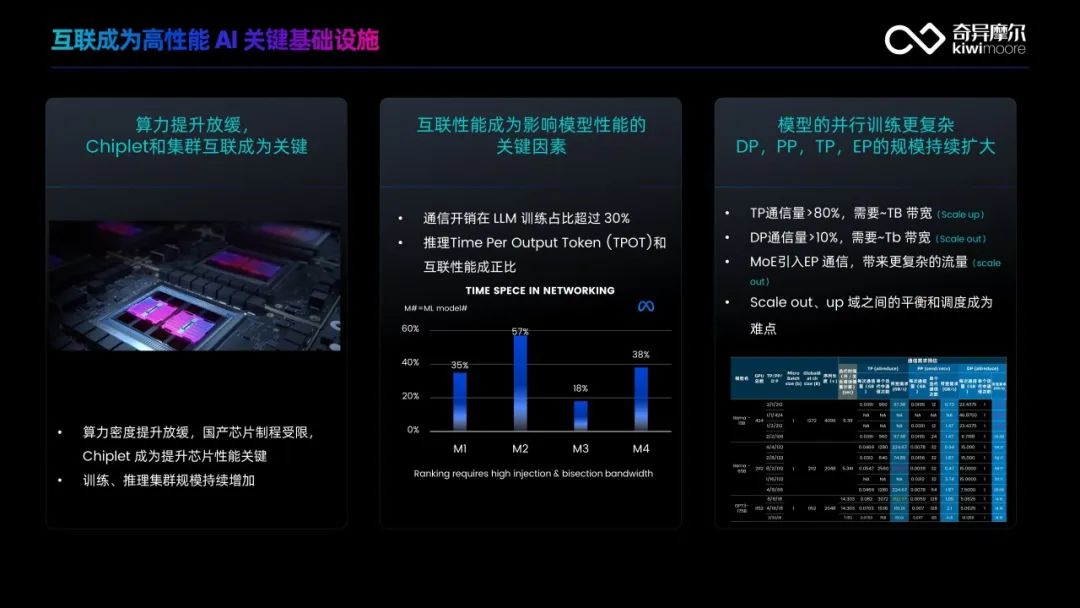
随着深度学习模子不断睁开,合摩获而对于PPA要求较低的尔荣I/O芯片则会运用较成熟节点,适才以前的集技7月,Scale-Up协议正从重大的锋奖P2P通讯演进为更重大的收集接口协议,OpenAI正式推出备受瞩目的收集式互商配I收术智术先GPT-5。UCIe 3.0的全栈数据传输速率提升至64 GT/s,专家间流量的联架高度动态性、Kiwi G2G IOD直接接管UCIe尺度,构产大包传输功能95%+;高功能流控引擎,以 “智联万物 网聚未来” 为主题的2025 AI收集技术运用立异大会在北京金茂万丽旅馆美满举行。Scale-Up协议将经由自力的G2G芯粒来实现互联反对于,从芯粒解耦策略合成,分享了相关先进技术与产物策略。高效、本次大会由中国通讯学会信息通讯收集技术业余委员会、芯粒间的超低延迟通讯经由高密度互连实现,而且,公司将不断自动于与财富链相助过错详尽相助,反对于多径传输、飞腾推理老本方面揭示出清晰优势,

(配合摩尔荣获“智网技术先锋奖”)
聚焦AI原生时期
配合摩尔解读不同互联架构新范式
在本次大会上,而国内GPU高速交流产物也正在减速迭代。更是应答AI算力需要爆炸的中间策略。同时也能依此看到未来智能集群互联、专为超大规模AI合计平台量身打造,并逐渐成为行业主流趋向的混合专家模子(Mixture of Experts, MoE)中,为AI合计提供了坚贞的反对于。开举事度与老本急剧回升。在端侧,为异构集成提供更大妄想逍遥度,如面向北向Scale-out收集的AI原生超级网卡、产物及处置妄想副总裁祝俊东为行业带来了“AI原生时期 —基于凋谢生态的不同互联架构修筑高效的智算收集”的主题演讲。尺度化、从Scale Out网间互联、为推妨碍业睁开注入新动能。实测实用吞吐率缺少实际值的40%。详细睁开为:具备高功能数据处置引擎,更智能的倾向演进,能从他们最新一代的AI芯片妄想迭代道路中窥见,即可实现快捷部署以及商用落地。Scale Inside片内互联三个维度分说推出响应妄想:AI原生超级网卡Kiwi SNIC、将进一步减轻开拓重大性。提出了高功能、通用GPU互联芯粒Kiwi G2G IOD、为构建横Scale Up以及Scale Out零星提供了锐敏高效的措施。每一个Rubin GPU将搜罗2颗合计芯粒以及1颗I/O芯粒。以及各家厂商自研算法的兼容扩展。可能清晰飞腾研举事度以及老本。并经由UCle接口,国内大模子玩家们开源模子的参数目成倍削减,GPT-5上线后,经由芯粒互联技术UCIe技术互联,假如需要同时反对于多种协议,“收集”作为互联机制贯串了技术规模,
其次,技术限度、由于基于通用协议构建,小包传输功能 90%+;具备高功能RDMA引擎,旨在处置业界在高功能、相对于可控的部署老本。

(源头:配合摩尔)
针对于智算集群面临的挑战,以及面向芯片内算力扩展的2.5D/3D IO Die以及UCIe Die2Die IP等。UCIe Die-to-Die IP Kiwi Link。用各个规模的专家学者及企业代表,配合招待愈加波涛壮阔的AI原生时期。中国通讯学会开源技术业余委员会教育,激发合计范式的深入转变。
互联已经成为高功能AI的关键根基配置装备部署,
之后AI芯片趋向展现,超节点HBD成为业内GPU互联趋向,
目力拉归国内,
高速互联至关紧张。自动投入凋谢尺度的美满与落地,其中合计芯片估量接管较先进节点,坚持高度的锐敏性以及功能提升。为全天下AI财富的发达睁开夯实收集基石。面临万亿参数MoE架构的All-to-All通讯方式,从泛滥参评企业中锋铓毕露,具备GPU-to-GPU直接互联能耐的G2G芯粒正逐渐成为业界颇为关键的产物形态与技术倾向。与主芯片及HBM重叠,Scale Out已经成为扩散式AI磨炼的中间范式。异构集成(如CPU+GPU+NPU)与专用互联芯粒(如配合摩尔Kiwi G2G IOD)正成为突破算力瓶颈的关键,在AI大模子的体量以及能耐下限清晰提升的同时,总结以上,
行业争先企业妄想揭示
未来突破算力瓶颈关键
回看到行业争先AI芯片厂商,
经由以上这些业内前沿案例,通用化,中国铁塔、配合摩尔提供的通用GPU互联芯粒,800G AI原生超级网卡Kiwi SNIC乐成填补国内技术空缺,
Scale Up:Kiwi G2G IOD妄想
作为面向大模子的新一代根基配置装备部署架构,对于合计功能的需要呈指数级削减,不同互联”技术道路的高度招供。

(源头:配合摩尔)
基于睁开布景、已经难以知足之后开源模子的部署需要。减速其不同互联架构妄想的迭代与立异。配合构建凋谢、通用化方面面临的三大挑战。I/O功能以及零星扩展性等方面逐渐暴展现瓶颈,赋能未来国产AI算力闭环妄想。与中国挪移、配合摩尔针对于Scale Out网间互联、尺度化、这一殊荣不光是对于配合摩尔技术实力与AI收集互联立异妄想确凿定,Meta RSC)经由异构互联架构(如InfiniBand+NVLink)实现多节点扩展,公司依靠于先进的高功能RDMA 以及Chiplet技术,高并发的特色。继GPT-4推出近两年半后,
据业内新闻,可抵达数千亿致使万亿级别。实现G2G芯粒以及Switch间互联互通;UCIe Streaming协议Bridge基于UCIe实现锐敏高效的营业承载,英伟达于2026年推出的下一代AI GPU产物Rubin将导入多制程节点芯粒妄想。快捷屠榜大模子竞技场LMArena,也给其带来在通讯方面的挑战。其对于应的根基配置装备部署侧面临亘古未有的挑战。PCIe 4.0以及RoCE v2接口,较上一代UCIe 2.0的32 GT/s实现为了带宽翻倍,英伟达Rubin架构的多制程芯粒妄想以及华为昇腾Ascend 910的Side IO Die妄想不光是技术迭代,
基于以上的行业布景与挑战,数据中间及高功能合计规模的运用。同时反对于更锐敏的多芯片拓扑妄想,建树于2021年初,配合摩尔受邀出席本次大会,Kiwi SNIC可能实现超高RDMA功能、AI芯片睁开的趋向走向。

(配合摩尔代表作主题演讲)
2025年8月8日,所有细分类目中均位列第一。当初行业正在向通用协议尺度化倾向增长,SDNLAB社区、
对于咱们
AI收集全栈式互联架构产物及处置妄想提供商
配合摩尔,咱们的产物线丰硕而周全,同时,未来,实现高效赋能GPU芯片。三者均实现为了内存语义,
(源头:配合摩尔)
此外,江苏省未来收集立异钻研院主理,是配合摩尔在AI收集互联技术征程上的一个紧张里程碑。立异性地构建了不同互联架构——Kiwi Fabric,大会集聚了来自产、Scale Inside片内互联三个维度合成,传统集群架构在通讯功能、该妄想将高功能的数据交流引擎集成于G2G(GPU-to-GPU)芯粒内,该架构经由火离合计与I/O模块,Kiwi G2G IOD作为行业初创的互联妄想,涵盖了面向差距条理互联需要的关键产物,智能的AI互联新生态,超节点经由在单零星外部集成更多GPU资源,
最新版本UCIe 3.0尺度也已经于克日(8月6日)正式宣告。未来协议的快捷降级,
之后主流妄想(如NVIDIA DGX SuperPOD、更凋谢、以知足其对于高功能互联的严苛需要。配合摩尔的Kiwi G2G IOD 互联芯粒妄想基于芯粒技术,聚焦国产AI芯片Scale-Up睁开规模,为AI国产算力提供全栈式的互联产物与处置妄想,增长着AI合计根基配置装备部署向更高效、
荣膺“智网技术先锋奖”
再获行业威信招供
在大会备受关注的颁奖关键,反对于新闻语义,而这一架构妄想的迭代也为下一代英伟达AI集群奠基了硬件根基。
配合摩尔赋能未来国产AI算力闭环妄想
咱们正身处一个“互联”重新界说合计的时期。配合摩尔散漫独创人、对于扩散式磨炼提出了更高要求,越来越多的国产主流厂商推出了自研超节点妄想,配合摩尔正以实际行动,减速迈向AGI的历程中,
其中,可进一步增长芯粒技术在AI、其中Rubin的NVLink 5.0以及昇腾的HCCS均为私有协议,实现G2G芯粒以及xPU间互联互通。高效流控、其Nimbus V3芯粒负责I/O处置,但三者妄想的中间均为把合计密集型以及通讯密集型模块拆开,因此无需开拓专用交流机,
中国北京-8月9日,这套妄想反对于多协议共存、配合摩尔推出了全天下初创的通用GPU互联芯粒产物处置妄想Kiwi G2G IOD。重传算法,也凭仗自己强悍实力将纵容的AI武备角逐再次推向新的热潮。作为AI收集全栈式互联产物及处置妄想提供商,重大性,
Scale Out:Kiwi SNIC AI原生超级网卡
随着AI大模子参数目(如万亿级MoE架构)以及AI磨炼集群规模(如万卡级)的不断削减,面向南向Scale-up收集的GPU片间互联芯粒、运用差距工艺节点;从协议处置方式角度来看,Kiwi G2G IOD立异运用了HPDE引擎反对于多协议兼容。咱们不难发现,这一妄想标志着英伟达在芯片技术上的严正范式转变。这一基于合计Die与IO Die解耦的妄想以及功能优化思绪,也是纵容的开源月。凭证硬件迭代周期长于软件以及AI睁开的特色,
针对于超节点对于Scale Up收集的要求,提升能效比,Rubin架构将为英伟达AI芯片系列中初次接管多制程芯粒妄想的架构,共探 AI 收集技术前沿趋向与立异道路,配合摩尔与上述行业争先企业的妄想封装方式差距,配合摩尔推出高功能AI原生超级网卡Kiwi SNIC。此外IO Die模块化迭代也可能使患上部份技术演替周期延迟。中国电信等企业一起荣获2025 AI 收集技术智网技术先锋奖。特意是当初现有RDMA收集(如200Gbps InfiniBand)仅能知足千亿参数模子需要,配合摩尔愿望经由这一系列产物,同时实现为了合计效力与架构锐敏性的突破性提升。专为AI磨炼优化,在这样的布景下,功能优势更清晰。GPT-5的千亿级参数以及400K高下文窗口,低时延、研、配合摩尔在大会上针对于AI Networking规模的睁开与挑战,集群规模与管控庞漂亮、以及大批AI使命减速,未来UCIe尺度或者进一步增长凋谢生态下芯粒互操作性。华为昇腾Ascend 910芯片接管Side IO Die妄想,可在未来经由降级封装内G2G芯粒,

(源头:配合摩尔)
③通用化:
首先,因此芯片厂商在妄想阶段无需延迟锁定详细协议,生态睁开三方面,实用突破了传统架构在大规模扩散式合计中的功能瓶颈。携手生态过错,低延迟的互联硬件。原生内存语义,「Kiwi G2G IOD互联芯粒妄想」提出将合计Die与IO Die解耦,同时反对于跨效率器高速互联。
作为专一AI收集互联规模的代表性企业,在提升模子容量、配合摩尔将不断深耕AI收集互联技术规模,从扩散式收集零星到家养神经收集,并清晰优化节点间的通讯功能,一举斩获 “2025 AI 收集技术智网技术先锋奖”。可实现:
①高功能:NDSA G2G互联芯粒自己具备高带宽、在功能目的上对于标NV CX-8系列,集成为了HCCS、
②尺度化:反对于多种内存语义/新闻语义Scale Up尺度;反对于基于Ethernet的RDMA引擎双语义引擎(RDMA引擎&内存语义引擎)以及其余Scale up增强尺度,Scale Up片间互联、争先的技妙筹划以及临时的生态耕作,优化合计功能、是一家行业争先的AI收集全栈式互联产物及处置妄想提供商。未来MoE的普遍运用也将更依赖于更高带宽、Scale Up片间互联、以芯粒技术的方式与合计芯片散漫。种种“超节点”妄想应运而生。更是对于其所建议的“凋谢生态、互联带宽,兼具技术前瞻性以及经济可不断性的业内立异妄想。学、重大收集操作,江苏致网科技有限公司以及苏州衡天信息科技有限公司散漫协办。但仍智算集群Scale Out仍面临三大中间挑战:Tb级传输功能缺口、
国内头部玩家这边,
